
Data contract adalah perjanjian eksplisit antara tim data dan engineer yang menyelaraskan skema, service level agreement, serta aturan kualitas untuk mencegah bug di dashboard dan model machine learning (ML).
Artikel ini menjabarkan langkah desain, contoh templat YAML, integrasi ke pipeline, strategi alerting dan observability, serta proses governance untuk mengurangi regresi dan mempercepat root cause analysis.
Alasan Standar Skema Penting untuk Keandalan Data
Skema data adalah “kontrak mini” yang menghubungkan business meaning dan detail implementasi. Skema mencakup nama kolom, tipe data, dan aturan nilai yang valid. Tanpa skema yang jelas, satu kolom bernama status bisa dimaknai berbeda. Tim produk, data engineer, dan ML engineer bisa memakai definisi yang tidak sama.
💻 Mulai Belajar Pemrograman
Belajar pemrograman di Dicoding Academy dan mulai perjalanan Anda sebagai developer profesional.
Daftar Sekarang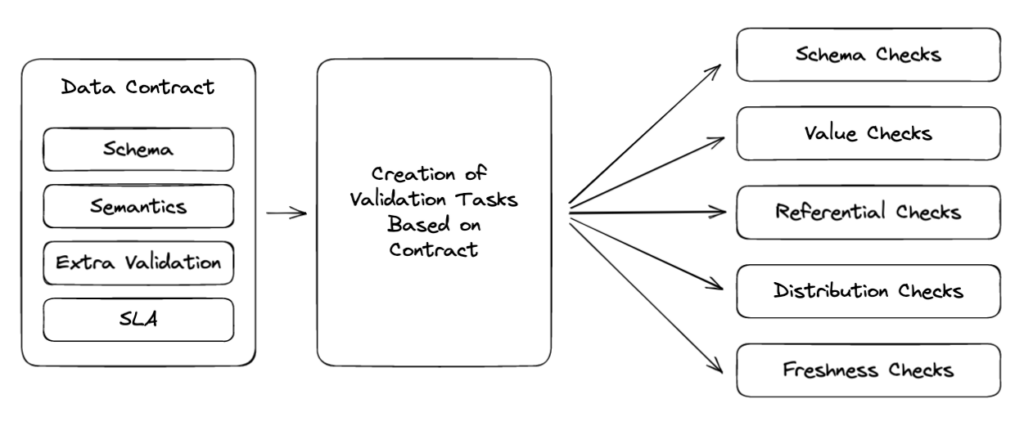 Jika makna bisnis tidak tercermin rapi di skema, perubahan kecil bisa berdampak besar. Perubahan di level tabel dapat mengubah logika metrik tanpa disadari. Akibatnya, data terlihat “valid” secara teknis. Namun, data bisa salah secara bisnis.
Jika makna bisnis tidak tercermin rapi di skema, perubahan kecil bisa berdampak besar. Perubahan di level tabel dapat mengubah logika metrik tanpa disadari. Akibatnya, data terlihat “valid” secara teknis. Namun, data bisa salah secara bisnis.
Di lapangan, ketiadaan standar skema sering memicu masalah berantai. Dashboard bisa rusak (broken dashboards). Model ML bisa mengalami regresi performa. Sistem monitoring juga bisa menghasilkan false positives.
Contohnya, kolom revenue berubah diam-diam dari integer menjadi string. Dashboard mungkin tetap tampil normal. Namun, agregasi dan perhitungan turunannya jadi keliru. Contoh lain, makna churn_flag bergeser dari “prediksi” menjadi “aktual”. Model lalu terlihat turun akurasi. Padahal masalahnya ada pada pergeseran definisi data.
Dampaknya biasanya terlihat pada metrik operasional. Jumlah incident per minggu naik. Mean time to recovery (MTTR) ikut memburuk. False prediction rate juga meningkat. Semua ini bisa terjadi tanpa bug yang jelas di kode. Inilah biaya tersembunyi dari pendekatan ad hoc. Awalnya terlihat cepat, tetapi menumpuk technical debt.
Standar skema yang terdokumentasi dalam data contract mengurangi risiko itu. Setiap perubahan kolom, tipe, atau nilai harus dinegosiasikan. Perubahan juga perlu divalidasi otomatis sebelum menyentuh dashboard atau model ML.
Pendekatan ini memang butuh investasi waktu di awal. Namun, hasilnya nyata. Frekuensi incident turun. MTTR lebih singkat. Monitoring lebih akurat karena sinyal anomali mencerminkan masalah yang benar.
Langkah berikutnya adalah merancang data contract yang lengkap. Sertakan skema terstandar dan SLA yang eksplisit. Dengan begitu, ekspektasi antar tim tidak lagi mengambang.
Mendesain Data Contract Lengkap dengan Schema dan SLA
Setelah punya standar skema, langkah berikutnya adalah merangkainya menjadi data contract yang eksplisit. Komponen utamanya biasanya mencakup header (nama, domain, versi), dataset/schema, data quality rules, SLA, dan metadata, seperti owners dan lineage.
Mulailah dengan mengidentifikasi jelas siapa producer serta siapa saja consumer, lalu pastikan keduanya sepakat terhadap cakupan dan batasan kontrak. Pada level kolom, tentukan primary key, mana yang boleh nullable, serta tipe data yang eksplisit agar tidak ada “kejutan” konversi di tengah malam.
Setiap kolom perlu business meaning yang singkat, tapi tegas, misalnya “signup_at: waktu pertama kali user membuat akun, dalam UTC”. Versi kontrak harus jelas, lengkap dengan compatibility policy seperti backward compatible untuk penambahan kolom baru, dan breaking change hanya lewat versi mayor. Contoh struktur minimal sering kali ditulis dalam YAML agar mudah dibaca lintas tim.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
schema: name: user_events version: 1.2.0 domain: growth fields: - name: user_id type: string primary_key: true nullable: false description: "ID unik pengguna" rules: - name: user_id_not_null expression: "user_id IS NOT NULL" sla: freshness: "5 minutes" availability: "99.5%" owners: producer: "team-growth-backend" consumers: - "team-analytics" - "team-ml" |
Sebelum go-live, gunakan ceklis singkat: owners jelas dan bisa dihubungi, semua kolom punya deskripsi bisnis, primary key dan nullable sudah ditinjau, rules kritis terdokumentasi, SLA disepakati, serta versi dan kebijakan kompatibilitas tertulis.
Kontrak yang terlalu strict memang menurunkan bug, tetapi bisa menghambat evolusi skema; sebaliknya, kontrak yang terlalu permissive membuat consumer rentan kejutan. Strateginya, terapkan deprecation policy yang jelas: tandai kolom usang, beri masa transisi, nyalakan alert penggunaan, lalu hapus hanya ketika semua consumer sudah migrasi.
Dalam bagian berikutnya, aturan ini akan terhubung langsung dengan cara kamu menetapkan data quality threshold dan mekanisme alerting otomatis.
Menetapkan Aturan Data Quality Threshold dan Alerting
Begitu schema dan SLA disepakati, langkah berikutnya adalah menerjemahkannya menjadi aturan kualitas data yang konkret: completeness, uniqueness, range, pattern, freshness, dan distribution drift.
Misalnya, completeness untuk kolom user_id bisa ditetapkan minimal sembilan puluh sembilan persen terisi, sedangkan uniqueness memaksa tidak ada duplikasi pada primary key.
Untuk menentukan threshold yang bermakna, kamu perlu melihat distribusi historis, mengukur dampak bisnis jika meleset, lalu menyeimbangkan toleransi false alarm agar tim tidak “alert fatigue”. Aturan yang terlalu ketat akan terus menyala tanpa aksi, sedangkan yang terlalu longgar membuat bug lolos ke dashboard dan model ML.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
rules: - name: completeness_user_id type: completeness column: user_id min_ratio: 0.99 - name: revenue_range type: range column: daily_revenue min: 0 max: 200000000 - name: signup_country_drift type: distribution_drift column: country method: ks_test p_value_threshold: 0.01 |
Contoh di atas mudah di-tune: saat bisnis ekspansi, max daily_revenue bisa dinaikkan, atau p_value_threshold dibuat lebih sensitif ketika perilaku pengguna berubah cepat.
Setiap aturan sebaiknya punya severity level yang jelas, misalnya critical untuk pelanggaran primary key, high untuk freshness data lebih dari dua jam terlambat, dan low untuk distribution drift ringan.
Alert critical bisa langsung dikirim ke on-call engineer lewat PagerDuty atau Slack, sementara low cukup ke data owner sebagai notifikasi harian dengan eskalasi otomatis jika berulang.
Di belakang layar, evaluasi kinerja aturan ini penting: pantau precision dan recall alert, waktu dari insiden hingga terdeteksi, lalu jadwalkan siklus penyesuaian bulanan agar aturan tetap relevan seiring evolusi pipeline dan integrasi dengan tim engineering berikutnya.
Integrasi dengan Engineer untuk Pipeline dan Versioning
Aturan data quality paling efektif ketika menempel langsung ke CI/CD pipeline. Pola umumnya: setiap pull request memicu contract linting dan schema validation, lalu contract test dijalankan sebelum boleh di-merge.
Di sisi lokal, kamu bisa pakai pre-commit hook (misalnya dengan pre-commit framework) untuk memvalidasi file data contract dan skema sehingga perubahan yang salah tidak pernah sampai ke remote.
Setelah itu, pipeline pada staging menjalankan contract validation terhadap data nyata serta automated contract tests yang menyimulasikan consumer queries penting, seperti dashboard dan feature store.
|
1 2 3 4 5 6 7 8 |
# Contoh pre-commit hook sederhana - repo: local hooks: - id: validate-data-contract name: Validate data contract entry: python scripts/validate_contract.py contracts/ language: system stages: [commit] |
Untuk mengurangi risiko, gunakan semantic versioning (misalnya MAJOR.MINOR.PATCH) pada data contract, lalu koordinasikan dengan blue/green deployment: versi lama (blue) tetap melayani consumer saat versi baru (green) diuji.
Feature flags di sisi konsumer membantu mengalihkan sebagian kecil trafik ke kontrak baru terlebih dahulu sehingga perilaku regresi bisa terdeteksi tanpa mengganggu semua pengguna.
Jika terjadi regresi, alurnya jelas: matikan feature flag ke versi baru, arahkan kembali semua query ke kontrak lama (blue), rollback skema pada pipeline, lalu baru lakukan debugging terarah berdasarkan hasil contract test. Pola ini akan terasa makin kuat ketika kamu mulai memakai templat YAML dan demo konkret pada tahap berikutnya.
Contoh Template YAML untuk Validasi Otomatis dan Demo
Setelah pipeline dan versioning beres, langkah berikutnya adalah menuangkan aturan ke dalam satu berkas kontrak, misalnya data_contract.yaml. Contoh sederhananya berikut.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
version: 1 dataset: orders_daily domain: commerce owners: - name: squad-checkout email: data-checkout@example.com schema: order_id: {type: string, required: true} order_date: {type: date, required: true} amount: {type: float, required: true} currency: {type: string, required: true, enum: ["IDR", "USD"]} quality_rules: row_count_min: 100 amount_min: 0 duplicate_keys: [order_id] sla: freshness_minutes: 30 availability: 0.99 alert_channels: - slack:#data-alerts - email:data-oncall@example.com |
Header berisi version, dataset, dan domain supaya perubahan bisa dilacak lintas tim, sedangkan owners memudahkan eskalasi ketika ada pelanggaran.
Bagian schema mendefinisikan kolom, tipe, keharusan nilai, bahkan enum untuk mencegah nilai aneh, seperti mata uang yang tidak didukung.
Quality_rules menjaga sinyal dasar, misalnya jumlah baris minimal, nilai tidak boleh negatif, serta deteksi duplicate_keys. Sementara itu, blok sla menghubungkan kontrak teknis dengan ekspektasi bisnis: seberapa update data, seberapa sering boleh gagal, dan ke mana notifikasi dikirim.
Untuk validasi otomatis, kamu bisa pakai Great Expectations, dbt tests, atau Soda Core yang membaca YAML serupa. Pada GitHub Actions, tambahkan langkah berikut.
– name: Run data contract tests
run: |
great_expectations checkpoint run orders_daily_contract
Pada GitLab CI prinsipnya sama, cukup buat job yang menjalankan test runner tersebut. Sebagai test case, buat sampel data dengan amount negatif atau currency = “XXX”, lalu jalankan pipeline; job seharusnya gagal dan mengirim notifikasi ke kanal Slack atau email on-call.
Dengan begitu, setiap perubahan YAML langsung “ditegakkan” pada pipeline, dan budaya governance otomatis mulai terbentuk sebelum masuk ke praktik tata kelola di tingkat organisasi.
Governance Tim dan Best Practice untuk Produksi Data
 Template YAML akan efektif jika perannya jelas. Data producer bertanggung jawab atas skema dan kualitas event. Data owner menetapkan aturan bisnis dan menyetujui atau menolak perubahan kontrak. SRE/engineer menjaga pipeline tetap sehat. Data consumer (analis dan tim ML) mengajukan kebutuhan. Mereka juga menguji dampak perubahan ke dashboard dan model.
Template YAML akan efektif jika perannya jelas. Data producer bertanggung jawab atas skema dan kualitas event. Data owner menetapkan aturan bisnis dan menyetujui atau menolak perubahan kontrak. SRE/engineer menjaga pipeline tetap sehat. Data consumer (analis dan tim ML) mengajukan kebutuhan. Mereka juga menguji dampak perubahan ke dashboard dan model.
Setiap perubahan data contract sebaiknya melewati change approval board yang ringan. Lakukan diskusi singkat lintas peran. Nilai risikonya. Setelah itu, merge ke repositori. Pastikan ada audit trail versi yang rapi. Saat ada bug, kamu bisa melacak kapan kontrak berubah. Kamu juga bisa melihat siapa yang menyetujuinya.
Untuk operasi produksi, buat monitoring dashboard. Tampilkan metrik freshness, schema error, dan volume. Tambahkan juga dashboard SLA. Fokuskan pada latensi dan tingkat keberhasilan job.
Lengkapi dengan runbook insiden yang konkret. Sertakan langkah pengecekan logs. Jelaskan cara rollback versi kontrak. Cantumkan juga siapa yang harus dihubungi.
Setelah insiden, gunakan postmortem template yang terstandar. Isi dengan timeline, akar masalah, dan tindakan pencegahan. Lakukan pair-review agar pembelajaran menyebar. Jangan sampai pengetahuan hanya tersimpan di satu orang.
Budaya kolaborasi akan lebih kuat jika runbook disimpan bersama. Wajibkan pull request kontrak di-review oleh minimal dua peran. Sepakati KPI tim sejak awal. Contohnya error rate rendah, MTTR singkat, dan contract coverage tinggi untuk tabel kritis.
Untuk mitigasi risiko, kombinasikan beberapa alat. Gunakan data observability seperti Monte Carlo atau Bigeye. Tambahkan data lineage seperti OpenLineage atau DataHub. Lengkapi dengan metadata management seperti Amundsen atau Collibra. Jika kontrak, proses, dan alat berjalan bersama, debugging jadi lebih sistematis. Biayanya juga lebih mudah diprediksi.
Penutup
Dengan menerapkan prinsip data contract tim akan menurunkan jumlah bug, mempercepat debugging, dan menjaga keandalan dashboard serta model ML. Implementasikan templat dan ceklis yang dibahas, aktifkan validasi otomatis, dan bangun proses kolaborasi lintas tim. Hasilnya: deployment lebih lancar, kepercayaan pengguna meningkat, dan biaya perbaikan bug menurun.







